GPU 메모리 계층 구조

GPU 메모리 계층 구조에 대한 부분을 우선 그림으로 표현한다면 아래와 같습니다.
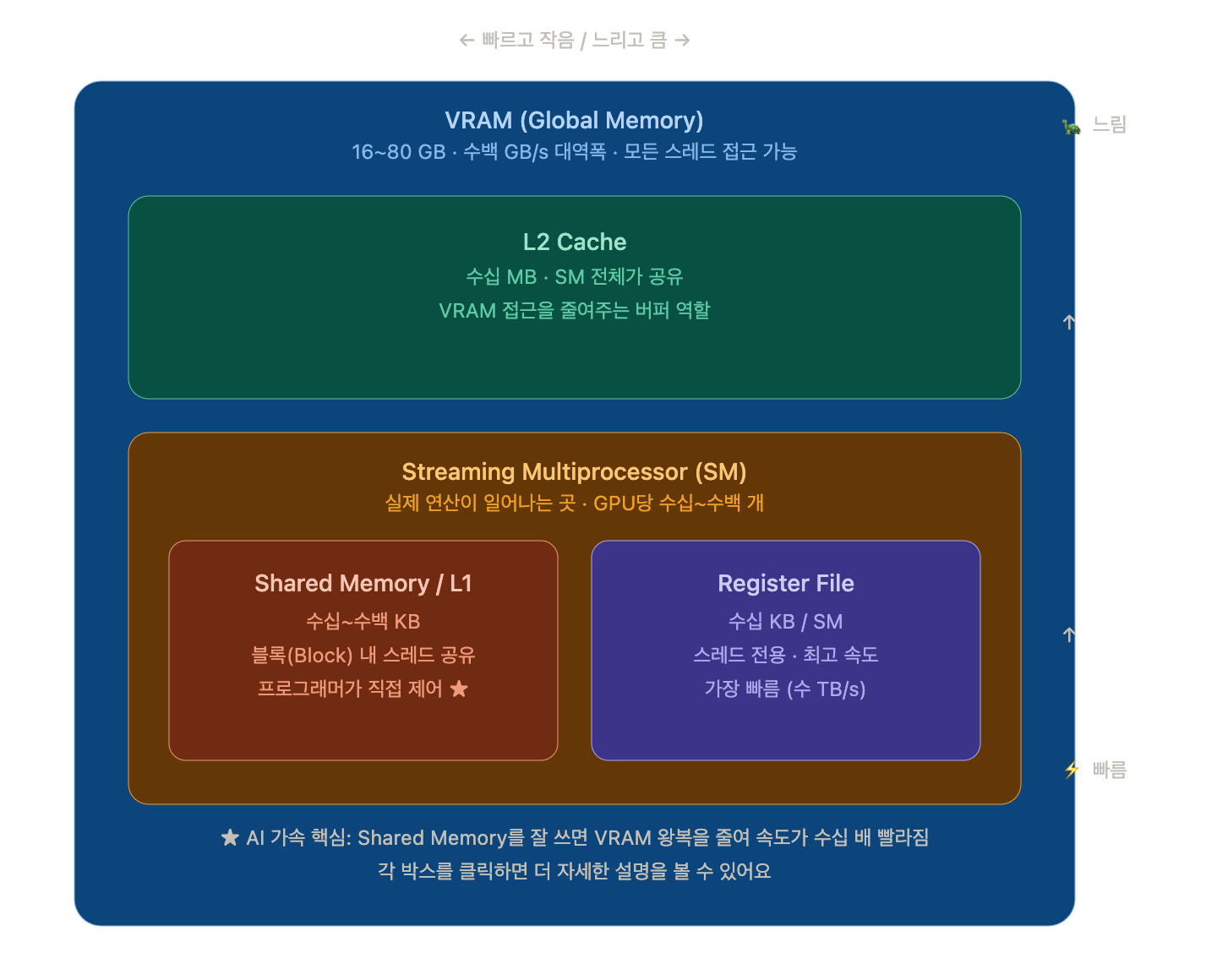
사실 CPU와 GPU는 구조적으로, 그리고 역할적으로 많이 다릅니다, CPU자체는 메모리를 개발자가 통제 할 수 없는데에 반해, GPU는 사용자가 메모리를 통제 할 수 있게 열어놨습니다.
그래서, GPU의 메모리를 어떻게 사용하느냐에 따라서, 그 효율이 결정되는것이죠
그래서 간단한게 실습을 진행하자면
💡
실습 환경 : DGX Spark Jupyter
vRAM 에서 데이터 이동 비용 측정
# 페이지 폴트 없애고 정확하게 측정하기
import torch, time
size = int(500 * 1024 * 1024 / 4)
# 핀 메모리 사용 (페이지 고정 → 오버헤드 제거)
cpu_pinned = torch.randn(size).pin_memory()
gpu_tensor = cpu_pinned.cuda()
# 워밍업
for _ in range(3):
_ = gpu_tensor.to(cpu_pinned)
torch.cuda.synchronize()
t0 = time.perf_counter()
for _ in range(10):
result = gpu_tensor.cpu()
torch.cuda.synchronize()
t1 = time.perf_counter()
bw = (500 * 10) / (t1 - t0) / 1024
print(f"GPU→CPU (보정): {bw:.1f} GB/s")결과
GPU→CPU (보정): 55.3 GB/sShared Memory 유무에 따른 속도 차이
# ── 실습 B: 캐시 친화적 접근 vs 비친화적 접근 ──────────────────
import torch
N = 4096
A = torch.randn(N, N, device='cuda')
# 워밍업
for _ in range(3):
_ = A @ A.T
# 행렬 곱 (GPU가 자동으로 shared memory 최적화)
torch.cuda.synchronize()
t0 = time.perf_counter()
for _ in range(100):
C = A @ A.T
torch.cuda.synchronize()
t1 = time.perf_counter()
print(f"행렬곱 (최적화됨): {(t1-t0)/100*1000:.2f} ms")
# 전치 없이 비연속 접근 (메모리 레이아웃 불리함)
A_bad = A.T.contiguous().T # 비연속 메모리
torch.cuda.synchronize()
t2 = time.perf_counter()
for _ in range(100):
C2 = A_bad @ A_bad
torch.cuda.synchronize()
t3 = time.perf_counter()
print(f"비연속 접근: {(t3-t2)/100*1000:.2f} ms")
결과
크기 | VRAM 내부 대역폭
-----------------------------------
100 MB | VRAM 내부: 212.4 GB/s
500 MB | VRAM 내부: 210.1 GB/s
1000 MB | VRAM 내부: 207.4 GB/s
5000 MB | VRAM 내부: 177.4 GB/s실습 결과
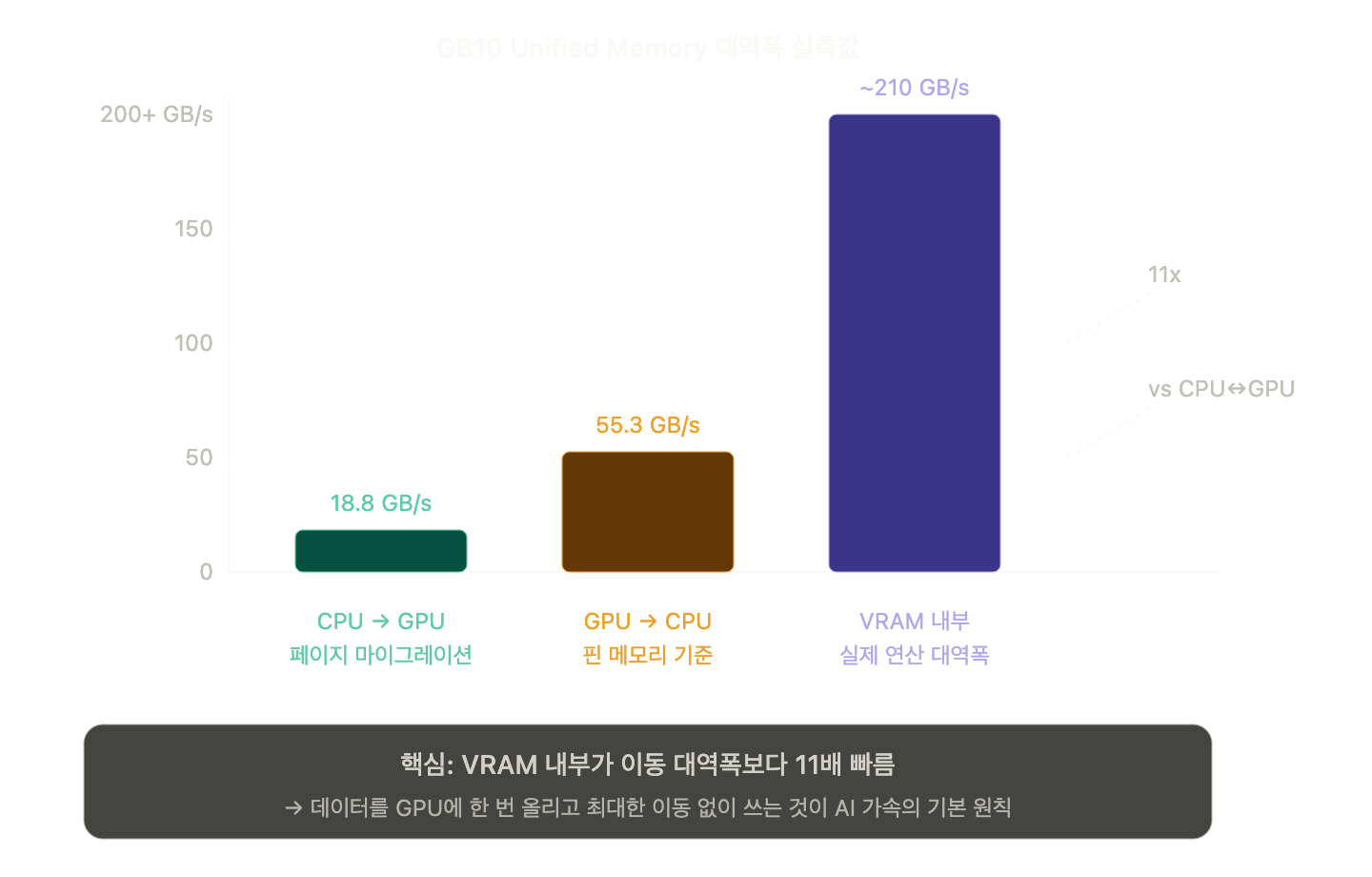
| 구간 | 측정값 | 의미 |
| CPU → GPU | 18.8 GB/s | 페이지 마이그레이션 오버헤드 포함 |
| GPU → CPU | 55.3 GB/s | 핀 메모리 기준 실제 대역폭 |
| VRAM 내부 | ~210 GB/s | GPU가 연산할 때 실제 속도 |
CPU↔GPU 이동은 VRAM 내부보다 최소 4~11배 느리다. 이게 AI 모델 최적화의 출발점이에요.
느린 코드: 연산할 때마다 CPU↔GPU 왔다갔다
빠른 코드: 처음에 GPU에 올리고 VRAM 안에서만 연산GB10은 Unified Memory라서 이 차이가 일반 GPU(PCIe 기준 수 GB/s)보다는 작지만, 그래도 차이가 존재한다는 게 핵심 입니다.
그리고 실습을 진행하다 share memory라는 개념이 나왔습니다.
이 개념은 다음 포스팅에서 계속 이어집니다.



