Roofline Model

GPU 메모리 계층과 Roofline Model
학습 환경: DGX Spark / NVIDIA GB10 Blackwell / Unified Memory 121.6GB / PyTorch 2.11.0+cu128
1. GPU 메모리 계층 구조
GPU 안의 메모리는 한 종류가 아니다. 빠를수록 작고, 클수록 느리다.

Register File 수십 KB / SM 스레드 전용 가장 빠름 (수 TB/s)
Shared Memory 수백 KB / SM 블록 내 공유 직접 제어 가능 ★
L1 / L2 Cache 수 MB 자동 관리
VRAM (Global) GB 단위 모든 스레드 접근 가장 느림
핵심: AI 가속의 핵심 제어 포인트는 Shared Memory다.
VRAM 왕복을 줄이고 Shared Memory를 최대한 활용할수록 속도가 빨라진다.
2. 데이터 이동 비용 — GB10 실측
GB10은 Unified Memory 아키텍처다. CPU와 GPU가 물리적으로 동일한 메모리 공간을 공유한다.
일반 GPU(PCIe 연결)와 구조가 다르지만, 이동 비용은 여전히 존재한다.
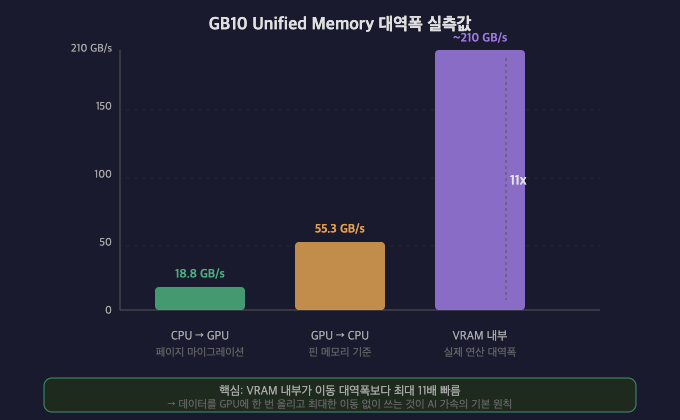
실측 결과
구간 | 대역폭 | 비고 |
CPU → GPU | 18.8 GB/s | 페이지 마이그레이션 오버헤드 포함 |
GPU → CPU | 55.3 GB/s | 핀 메모리(pin_memory) 기준 |
VRAM 내부 | ~210 GB/s | 실제 연산 대역폭 |
핵심 인사이트
VRAM 내부가 CPU↔GPU 이동보다 최소 4~11배 빠르다.
# 느린 코드: 연산마다 CPU↔GPU 왕복
for batch in dataloader:
result = model(batch.cuda())
result.cpu() # 매번 이동
# 빠른 코드: 한 번 올리고 VRAM 안에서만 처리
data = data.cuda()
for _ in range(steps):
result = model(data) # VRAM 내부만 사용
SSD → GPU 데이터 이동 경로
원래는 SSD에서 GPU로 데이터를 보낼 때 CPU를 반드시 경유한다.
기존: SSD → CPU RAM → GPU VRAM (복사 2회, CPU 개입)
GDS: SSD ──────────→ GPU VRAM (복사 1회, CPU 우회)
GB10: SSD → Unified Memory (CPU/GPU 구분 없이 동일 공간)
Tenstorrent / PIM이 노리는 것: 이 이동 횟수를 0으로 만드는 것.
연산장치를 메모리 옆에 붙이면 이동 자체가 사라진다.
3. Roofline Model
왜 나왔나 — Memory Wall
1980년대 이후 CPU 성능은 약 10,000배 향상됐지만, 메모리 대역폭은 약 100배밖에 향상되지 않았다.
이 격차를 Memory Wall이라 부른다.
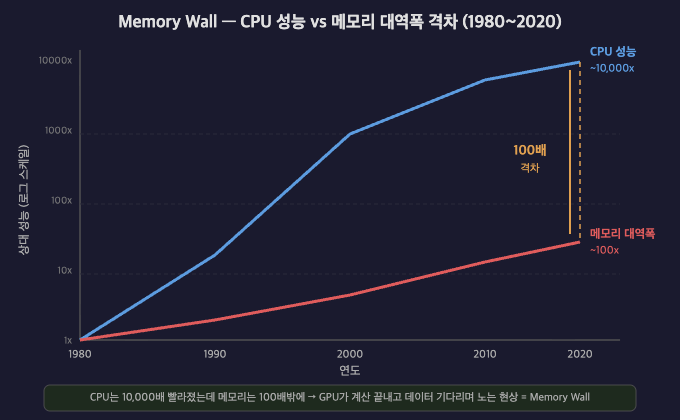
CPU: 계산 끝났어, 다음 데이터 줘
메모리: 잠깐만, 아직 읽는 중...
CPU: ............. (대기)
GPU 시대에는 이 문제가 더 극단적이 된다.
연산 성능은 폭발적으로 늘었지만 메모리 대역폭은 따라가지 못했다.
개념 정의
Arithmetic Intensity (AI) = 연산량 (FLOP) / 메모리 이동량 (Byte)
AI 값 | 판단 | 의미 |
Ridge Point 미만 | Memory-Bound | 메모리 대역폭이 병목 |
Ridge Point 이상 | Compute-Bound | 연산 성능이 병목 |
Ridge Point = 연산 성능 (FLOP/s) / 메모리 대역폭 (Byte/s)
GB10 기준 실측
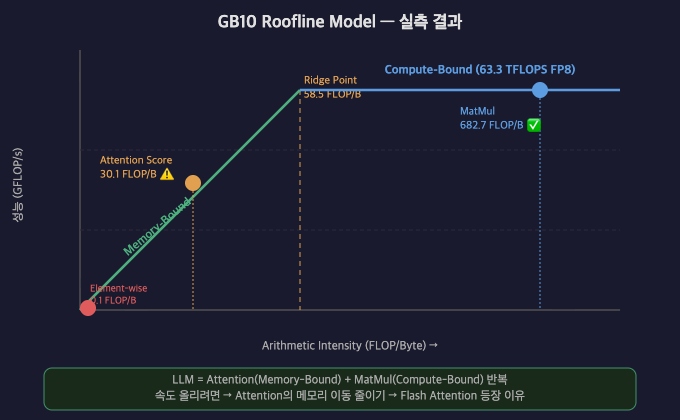
VRAM 대역폭: 210 GB/s (직접 측정)
FP8 연산 성능: 63.3 TFLOPS (직접 측정)
Ridge Point: ~301 FLOP/Byte
주요 AI 연산의 Arithmetic Intensity
연산 | AI | 판정 |
Element-wise (ReLU 등) | 0.1 FLOP/Byte | Memory-Bound ⚠️ |
Attention Score | 30.1 FLOP/Byte | Memory-Bound ⚠️ |
MatMul | 682.7 FLOP/Byte | Compute-Bound ✅ |
결론: LLM의 핵심 연산인 Attention은 Memory-Bound다.
속도를 올리려면 연산량이 아니라 메모리 이동량을 줄여야 한다.
4. 정밀도별 성능 비교 — GB10 실측
정밀도 | 실측 성능 | BF16 대비 | 특징 |
BF16 | 9.4 TFLOPS | 1.0x | 기준 |
FP8 Weight Only | 8.9 TFLOPS | 0.9x | 메모리 절약 목적, 연산은 BF16 변환 |
FP8 Dynamic | 41.8 TFLOPS | 4.4x | 활성화+가중치 모두 FP8, 네이티브 연산 |
FP8 raw (MatMul) | 63.3 TFLOPS | 6.7x | 순수 행렬 곱 기준 |
FP8 Weight Only가 BF16보다 느린 이유 (Roofline 관점)
FP8 저장 → 연산 전 BF16 변환 → 연산
↑
이 변환이 메모리 왕복 추가
→ Arithmetic Intensity 낮아짐 → 더 Memory-Bound
FP8 Dynamic이 4.4배 빠른 이유
FP8 저장 → FP8 그대로 연산
데이터 크기 절반 → 같은 대역폭으로 2배 처리
→ Roofline에서 오른쪽(Compute-Bound)으로 이동
5. 핵심 요약
1. GPU 메모리는 계층이 있다
Register > Shared Memory > L2 Cache > VRAM
빠를수록 작고, 클수록 느리다
2. 데이터 이동은 비싸다
VRAM 내부(210 GB/s) >> CPU↔GPU 이동(18~55 GB/s)
한 번 올리고 VRAM 안에서만 써라
3. Roofline = 병목 진단 도구
"느린 게 연산 때문인가, 메모리 때문인가"
잘못 짚으면 최적화가 의미없다
4. AI 모델 대부분은 Memory-Bound
Attention, LayerNorm, Element-wise = 전부 메모리 병목
Flash Attention, FP8 Dynamic이 나온 이유
5. 정밀도 낮추면 Roofline이 개선된다
데이터 크기 절반 → 메모리 이동 절반
→ Memory-Bound에서 Compute-Bound 쪽으로 이동
6. 다음으로 연결되는 개념
- Flash Attention: Attention의 메모리 왕복을 줄이는 알고리즘
- Triton: 메모리 타일링을 직접 제어하는 커널 작성 도구
- PIM / Tenstorrent: 메모리 안에 연산장치를 넣어 이동 자체를 없애는 아키텍처
- CXL: 여러 노드의 메모리를 하나처럼 쓰는 인터커넥트
학습일: 2026년 5월
환경: DGX Spark / GB10 Blackwell / Unified Memory 121.6GB



