Share Memory

Shared Memory와 메모리 접근 패턴
학습 환경: DGX Spark / NVIDIA GB10 Blackwell / Unified Memory 121.6GB / PyTorch 2.11.0+cu128
이전 내용: GPU 메모리 계층 + Roofline Model
1. Shared Memory란 무엇인가
Roofline에서 Memory-Bound 판정이 나오면 해결책이 필요하다.
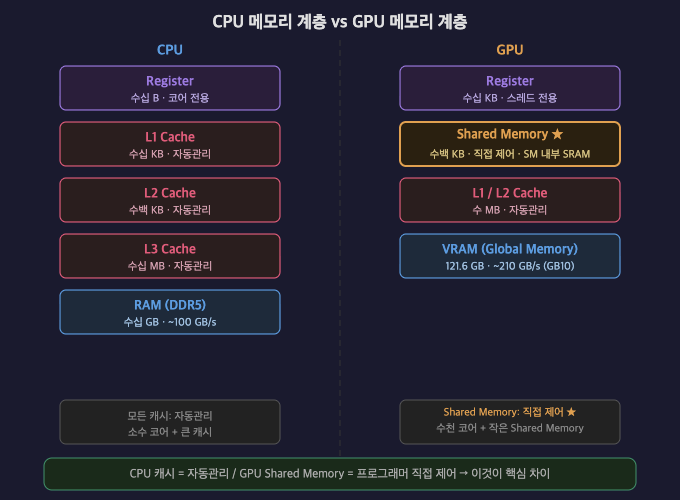
핵심 도구가 바로 Shared Memory — GPU SM 칩 안에 물리적으로 박혀있는 초고속 SRAM이다.
VRAM (Global Memory)
→ GPU 칩 바깥에 존재 (LPDDR5X / HBM)
→ SM과 버스로 연결 → 느림 (~210 GB/s)
Shared Memory
→ SM 칩 안에 직접 박혀있는 SRAM
→ 연산 코어 바로 옆에 붙어있음
→ 수 TB/s (VRAM의 10~20배)
핵심 아이디어
VRAM만 쓸 때:
Thread 1 → VRAM 왕복
Thread 2 → VRAM 왕복 (같은 데이터인데 각자 읽음)
Shared Memory 활용:
VRAM → Shared Memory (1회만 로드)
Thread 1 ↗
Shared Memory에서 같이 읽음
Thread 2 ↗
2. CPU 캐시와 뭐가 다른가
완전히 다른 물리 메모리다.
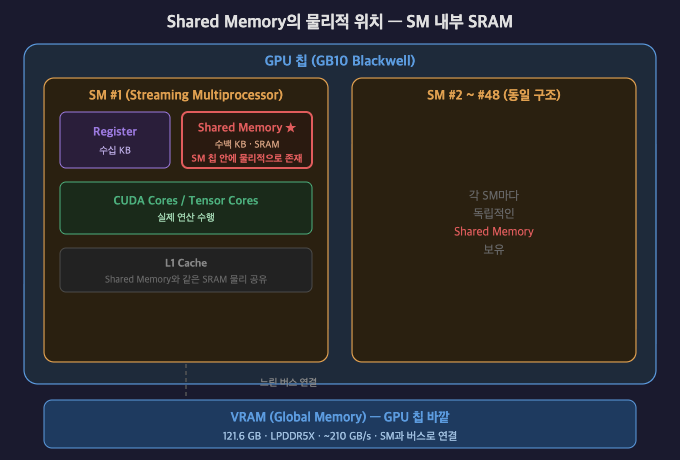
결정적 차이 — 제어권
CPU 캐시 | GPU Shared Memory | |
물리 위치 | CPU 패키지 내 SRAM | GPU SM 내 SRAM |
관리 주체 | 하드웨어 자동 | 프로그래머 직접 |
제어 가능 | ❌ 불가 | ✅ 코드로 제어 |
비유 | 자동 창고 | 내가 직접 쓰는 작업대 |
설계 철학 차이
CPU 소수 코어 + 큰 캐시
"코어 하나를 최대한 빠르게"
캐시가 알아서 자주 쓰는 데이터 유지
GPU 수천 코어 + 작은 Shared Memory
"수천 개를 동시에 돌리기"
프로그래머가 공유 데이터 직접 관리
GB10에서 특이한 점
일반 GPU: CPU RAM ≠ GPU VRAM (물리적으로 분리)
GB10: CPU RAM = GPU VRAM (Unified Memory, 같은 물리 공간)
단, SM 내부 Shared Memory는 GB10에서도 별개로 존재
→ SM 칩 안에 고정된 SRAM
3. 실습으로 확인한 것들
Triton 벡터 합 커널 (성공)
@triton.jit
def vector_add_kernel(x_ptr, y_ptr, out_ptr, N, BLOCK):
pid = tl.program_id(0)
offs = pid * BLOCK + tl.arange(0, BLOCK)
mask = offs < N
x = tl.load(x_ptr + offs, mask=mask)
y = tl.load(y_ptr + offs, mask=mask)
tl.store(out_ptr + offs, x + y, mask=mask)
결과: 0.009ms / PyTorch 오차 0.00000000 ✅
Triton의 블록 단위 프로그래밍 = 내부적으로 Shared Memory 자동 활용
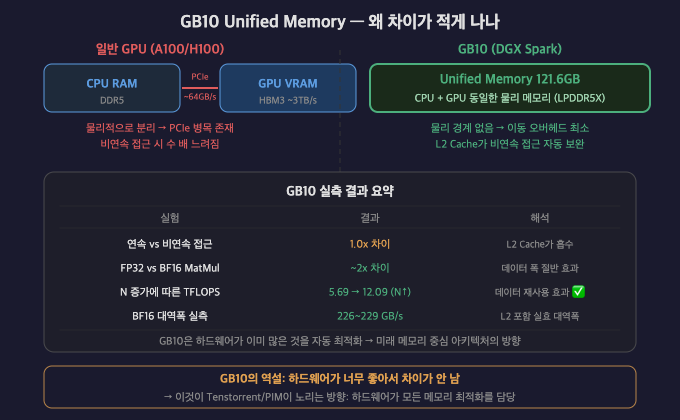
행렬 크기(N)별 TFLOPS — 데이터 재사용 효과
N | FP32 (ms) | BF16 (ms) | FP32 TFLOPS | BF16 TFLOPS |
512 | 0.065 | 0.047 | 4.13 | 5.69 |
1024 | 0.396 | 0.203 | 5.43 | 10.58 |
2048 | 3.150 | 1.422 | 5.45 | 12.09 |
4096 | 24.451 | 11.534 | 5.62 | 11.92 |
두 가지 효과 확인:
① N이 커질수록 TFLOPS 증가 → Shared Memory 데이터 재사용 효과
Arithmetic Intensity = 2N³ / (3N² × 4bytes) = N/6
N이 클수록 같은 데이터를 더 많이 재사용 → 더 효율적
② BF16이 FP32보다 ~2배 빠름 → 데이터 폭 절반 효과
메모리 이동량 절반 → Roofline에서 오른쪽으로 이동
4. GB10에서 차이가 적게 나는 이유
실습을 하다보면 연속/비연속 접근 차이가 거의 없다. 이건 실험 오류가 아니라 GB10의 설계 특성이다.
일반 GPU (A100) GB10
비연속 접근 → 캐시 미스 폭발 거대한 L2 Cache가
→ 수 배 느려짐 비연속 접근 자동 보완
차이가 명확함 → 차이가 거의 없음
GB10이 자동으로 해주는 것:
- 비연속 접근 → 메모리 컨트롤러가 요청 재정렬
- 자주 쓰는 데이터 → L2 Cache 자동 보관
- 작은 행렬 → 캐시에 통째로 올려버림
이게 미래 아키텍처와 연결된다
과거: 프로그래머가 Shared Memory 직접 관리
현재(GB10): 하드웨어가 점점 자동으로 해줌
미래(Tenstorrent/PIM): 메모리 안에서 연산 → 이동 자체가 없어짐
GB10은 그 중간 어딘가에 위치한 아키텍처다.
5. 핵심 요약
1. Shared Memory는 SM 칩 안의 SRAM
VRAM(칩 바깥)과 물리적으로 완전히 다름
VRAM보다 10~20배 빠름
2. CPU 캐시와의 결정적 차이 = 제어권
CPU 캐시: 하드웨어 자동관리 (건드릴 수 없음)
Shared Memory: 프로그래머가 직접 제어 (최적화 가능)
3. Shared Memory 활용법 = 타일링(Tiling)
자주 쓰는 데이터를 VRAM에서 한 번만 읽어
Shared Memory에 올려두고 스레드들이 나눠씀
4. GB10에서는 하드웨어가 많은 것을 자동 처리
→ 차이가 잘 안 보이는 게 버그가 아니라 특성
→ 미래 메모리 중심 아키텍처의 방향
5. N이 클수록 TFLOPS가 올라가는 것 확인
→ 데이터 재사용 = Shared Memory 효과
→ Arithmetic Intensity = N/6이 커지는 것과 일치
6. 다음으로 — Flash Attention
Shared Memory 개념을 실무에서 가장 극적으로 활용한 사례가 Flash Attention이다.
일반 Attention VRAM 왕복 반복
→ Q, K, V 전체를 VRAM에 올려두고
→ 소프트맥스, 가중합 계산마다 왕복
Flash Attention Shared Memory 타일링
→ 타일 단위로 Shared Memory에 올려두고
→ VRAM 왕복 횟수 대폭 감소
→ 시퀀스 길이에 선형적 메모리 사용
→ 실측 2~4배 속도 향상
이게 다음 챕터의 주제다.
학습일: 2026년 5월
환경: DGX Spark / GB10 Blackwell / Unified Memory 121.6GB



